 Generating valuable predictive analytics from your data assets is hard, as most teams working on and building these capabilities take the difficult route.
Generating valuable predictive analytics from your data assets is hard, as most teams working on and building these capabilities take the difficult route.
Experimentation on, and the development of, these powerful predictive capabilities in the cloud makes life much easier and cheaper not to leverage. Many enterprises greatly lack the right skills to select the right tools before the job even begins. Early decisions play a massive part in the overall and sustainable success when it comes to building predictive capabilities.
To create impactful and valuable predictive insights through machine-learning and deep-learning models, copious amounts of data and effective ways to clean all that data is required to perform feature engineering on it which is a way to deploy your models and monitor them.
It only makes sense to run these functions in the cloud where the required resources are available in a cost-effective manner and more importantly, as and when needed, releasing the compute resources only when required and therefore reducing cost.
Moreover, in recent times, cloud providers have put significant effort into building out their service offerings to support the complete machine-learning life cycle.
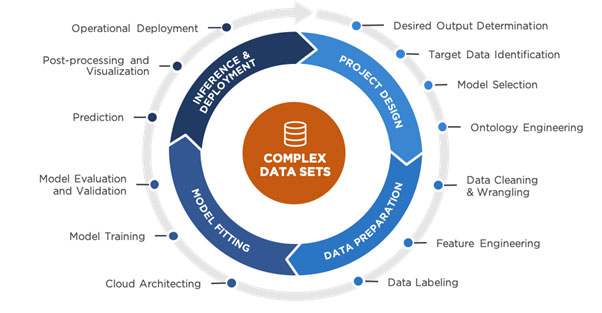
Here are principles to consider in selecting the right tools before experimenting on and building predictive capabilities:
1. Ability to scale up and scale out predictive model training
Working in an environment where it is easy and cost-effective to beef up the individual processing nodes (scale-up) as well as increasing the number of processing nodes easily (scale-out) is imperative for productive and cost-effective experimentation and ultimately maintaining a valuable predictive capability.
2. AutoML and automatic feature engineering
The complexity of tasks in the machine-learning process and methodologies has increased; the rapid growth in the need for machine learning predictive capabilities through specific applications has created the demand for AutoML that can provide a quick turnaround in the experimentation phases.
The cloud machine-learning and deep-learning platforms tend to have their collection of algorithms, and they often support external frameworks in at least one language or as containers with specific entry points.
3. Pre-trained models
Pre-trained models can be used to provide a predictive outcome to a similar context. Instead of building a model from scratch one can utilise a well-trained and matured machine-learning model to achieve a quick initial capability specifically to prove a concept and value for further investment. The variety of such pre-trained models is ever growing, specifically as part of the cloud-based ML services.
4. Tuned AI services
The major cloud platform providers offer matured and tuned predictive services for many applications. Some of these services have been trained using magnitudes more data that would be available to any one organisation and as we know more data to train on provides for a more accurate predictive outcome.
 5. Machine-learning models deployment into production
5. Machine-learning models deployment into production
Once a machine-learning model has been matured and improved through various iterations, it does not create value if not deployed into production. Deploying a predictive capability, monitoring the data submitted over time and retraining regularly is all key for a continuous well-performing capability. Having this in the cloud, close to the experiments with scaling capabilities, makes sense.
6. Cost management
The flexibility and resulting cost savings in the cloud when it comes to experimenting, developing and deploying predictive capabilities is massive. The nature of the machine-learning lifecycle (diagram above) allows for the provision of sufficient hardware and infrastructure required at peak loads in the process. Therefore, it does not make sense to have this available in a non-shared model. Not considering this and utilising shared services have been the downfall of many predictive initiatives historically, specifically from a cost perspective.
7. ML as a service
Utilising mature environments where ML services are costed and utilised allows the team to focus on real value generation when it comes to developing predictive capabilities and to not get stuck in a complex environment and infrastructure issues and maintenance.
In recent years, organisations had to cope with the rapid deployment of new, modern data technologies alongside legacy infrastructure. These additions, from data lakes, schema on read methodologies and real-time analytics, have increased the complexity in data architectures with the risk of slowing down the agility to deliver answers at the speed of business even further.
Now more than ever, as companies navigate the unprecedented crisis caused by Covid-19, the need for agile analytics and focus to deliver insights and answers to everchanging business questions is imperative. Decisions, with regards to the right tools for the job, is a big enabler.
For more, visit ovationsgroup.com, or find the company on Facebook, LinkedIn, Twitter and Instagram.
- Article written by Johan du Preez, capability architect at Ovations Group
- This promoted content was paid for by the party concerned


